LightGBM特征重要度和可视化
总结了一些在python中使用关于LightGBM模型展示特征重要度和可视化决策树的方法。
训练模型-原生接口:
# One-hot encoding
# feature_categorical = ['Model']
# dataframe = pd.get_dummies(dataframe, columns=feature_categorical)
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': ['auc', 'binary_error'],
'num_leaves': 30,
'max_depth': 8,
'learning_rate': 0.02,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 12,
'num_threads': 32,
'verbosity': 1
}
lgb_train = lgb.Dataset(dataframe.iloc[:-val_size][use_feature_name], dataframe.iloc[:-val_size]['label'])
lgb_val = lgb.Dataset(dataframe.iloc[val_size:][use_feature_name], dataframe.iloc[val_size:]['label'])
model = lgb.train(lgb_params, lgb_train, num_boost_round=20, categorical_feature=use_categorical_feature,
feature_name=use_feature_name, valid_sets=[lgb_val], early_stopping_rounds=10, verbose_eval=1,
feval=None)
训练模型-sklearn接口:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
feature = dataset.data
label = dataset.target
train_x, test_x, train_y, test_y = train_test_split(feature, label, test_size=0.2)
clf = lgb.LGBMClassifier(num_leaves=31, learning_rate=0.05, n_estimators=20)
clf.fit(train_x, train_y, eval_set=[(test_x, test_y)], eval_metric='auc', early_stopping_rounds=5)
print(clf.feature_importances_)
特征重要度画图:
plt.figure(figsize=(12, 6))
lgb.plot_importance(model, max_num_features=30)
plt.title('feature_importance')
plt.savefig('./feature_importance.png')
plt.show()
大概长这样,比较丑,还是自己拿csv数据额外用plot画吧: 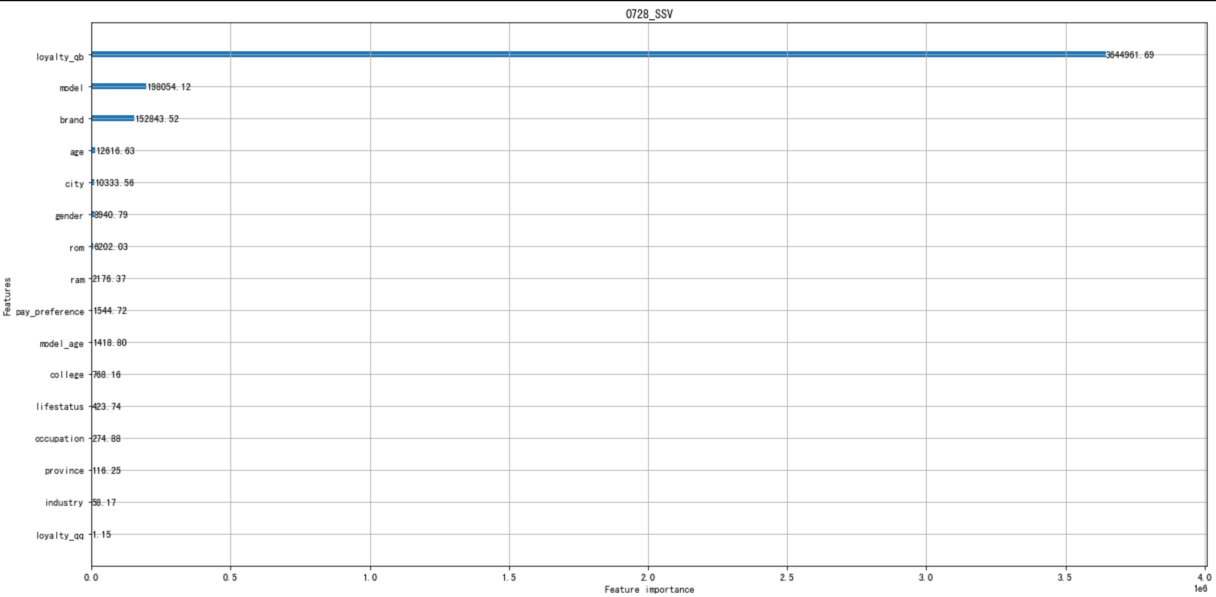
特征重要度保存为csv:
importance = model.feature_importance(importance_type='gain') # split
for (feature_name, importance) in zip(use_feature_name, importance):
print(feature_name, importance)
feature_importance = pd.DataFrame({'feature_name': use_feature_name, 'importance': importance})
feature_importance.to_csv('feature_importance.csv', index=False)
打印决策树-方式一(不清晰,不推荐)
fig = plt.figure(figsize=(100, 100))
ax = fig.subplots()
lgb.plot_tree(model, tree_index=0, ax=ax)
plt.savefig('./model_tree.png')
plt.show()
大概长这样,黑白的,并且清晰度低: 
打印决策树-方式二(推荐)
# 需要安装graphviz,python环境和系统环境都要安装
# pip install graphviz pydotplus matplotlib
# $sudo yum install graphviz
graph = lgb.create_tree_digraph(model, tree_index=0, show_info=['data_percentage', 'internal_value', 'internal_weight'], orientation='vertical')
graph.view(directory='./', filename='model_tree.gv.pdf')
大概长这样,黑白的,会保存为一个pdf文件和一个gv文件,pdf文件清晰度很高: 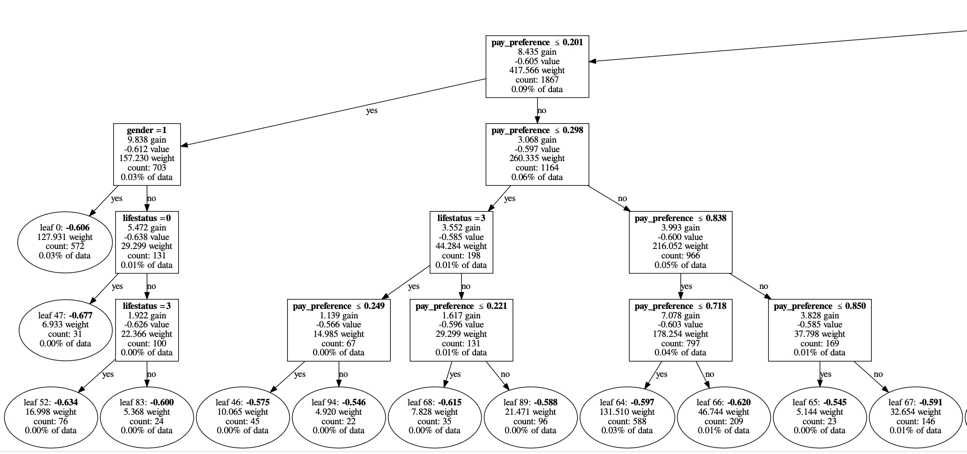
打印决策树-方式三(需要sklearn接口)
from sklearn.tree import export_graphviz
import pydotplus
dot_data = export_graphviz(
clf,
out_file=None,
feature_names=df.columns[:-1],
class_names=["good", "bad"],
filled=True,
rounded=True,
special_characters=True,
)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png('./tree.png')
with open('tree.dot', encoding='utf-8') as f:
dot_graph = f.read()
graph = graphviz.Source(dot_graph.replace('helvetica', 'MicrosoftYaHei')) # 如果提示警告可以将MicrosoftYaHei改为FangSong
graph.view()
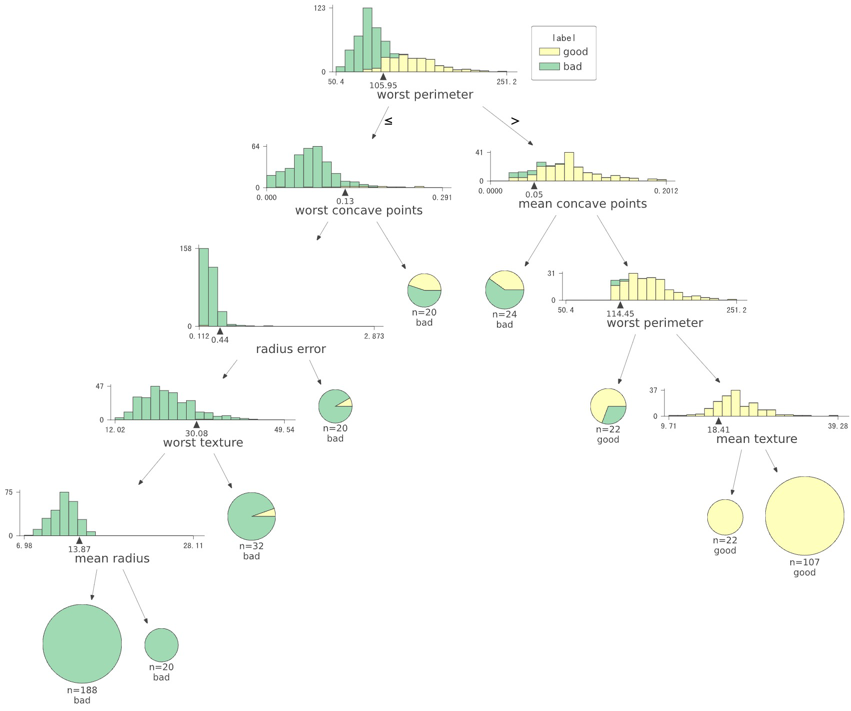
打印决策树-方式四(推荐,高端大气上档次)
首先安装依赖包
pip install dtreeviz # install dtreeviz for sklearn
pip install dtreeviz[xgboost] # install XGBoost related dependency
pip install dtreeviz[pyspark] # install pyspark related dependency
pip install dtreeviz[lightgbm] # install LightGBM related dependency
然后调用相关接口打印决策树和决策路径
import dtreeviz
# 打印决策树
graph = dtreeviz.trees.dtreeviz(clf.booster_, feature, label, tree_index=1, target_name='label', orientation='TD',
feature_names=dataset.feature_names, class_names=['good', 'bad'])
graph.save('./tree.svg')
# 图框形式-打印一个例子的决策路径,就是加上X这个参数
graph = dtreeviz.trees.dtreeviz(clf.booster_, feature, label, tree_index=1, target_name='label', X=test_x[0],
feature_names=dataset.feature_names, class_names=['good', 'bad'])
# 文字形式-打印一个例子的决策路径,得到根据这个例子所需要的特征圈选范围
print(dtreeviz.trees.explain_prediction_path(clf.booster_, test_x[0], tree_index=1, feature_names=dataset.feature_names, explanation_type="plain_english"))
保存图长这样,彩色分布: